
Editor's note: "Trends" represent the development of things, and its goals can be vague, but this continuous progress is reflected in the data is clear. In April last year, Tesla AI director Andrej Karpathy published an A Peek at Trends in Machine Learning, revealing the total number of machine learning papers (arxiv), deep learning frameworks, CNN models, optimization algorithms and research trends. Just a few days ago, he updated a wave of data and saw a very interesting change.
Note: This article has updated the total number of papers and popular frame rankings, and the rest remains the April 2017 data.

It seems that there is a little less
I don't know if readers have used Google Trends. This is a very cool tool - enter keywords and you can see the changes in Google search results over time. Now, we also have a machine learning paper library arxiv-sanity, which has accumulated 43108 arxiv related papers in the past 6 years, so why don't we fall into the cliché and look at the evolution of machine learning research in the past 6 years? What about the situation?
Note: The paper library was created by Andrej Karpathy. Since machine learning involves a lot of content, a large part of the text is centered around deep learning, especially the familiar field of Andrej Karpathy.
Arxiv singularity
First let's take a look at the total number of papers on arxiv-sanity (cs.AI, cs.LG, cs.CV, cs.CL, cs.NE, stat.ML). As of April last year, arxiv-sanity had a total of 28,303 machine learning papers. In March 2017 alone, nearly 2,000 new papers were published in the database, and the academic results of machine learning ushered in an outbreak.
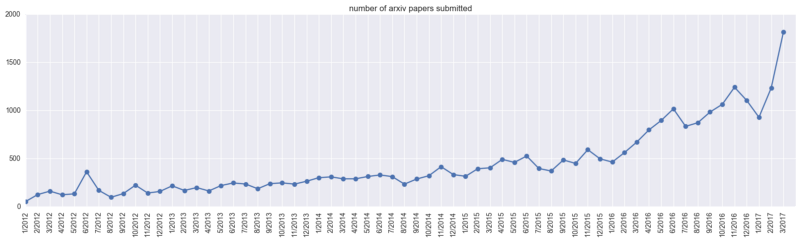
ML paper submission volume change on arxiv
In just one year, the total number of papers on arxiv-sanity has exceeded 43,000. Considering the popularity of machine learning international summits in recent years, let's take a look at several major conferences (after April last year). "Sucking gold" ability:
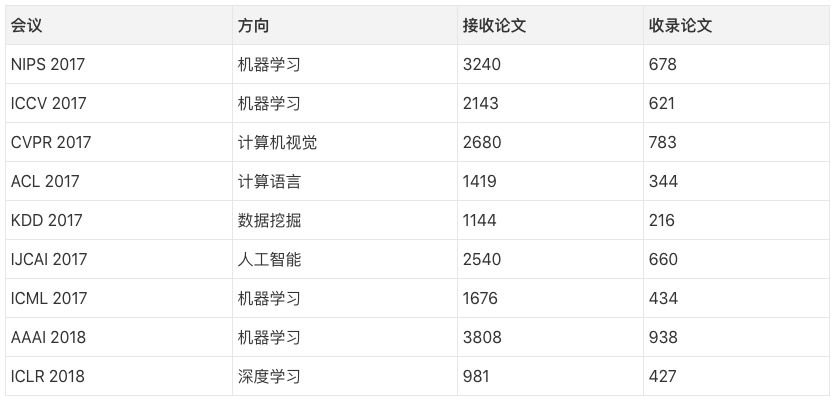
Although the papers submitted for the conference may not be submitted to arxiv, it can be seen that before 2017, the total number of papers on arxiv-sanity was less than 30,000, and last year, the conference attracted nearly 20,000 articles. Submissions, as well as other top-level data are not included, the heat of machine learning can be seen.
Of course, this also brings up a problem, that is, scholars need to read a large number of papers to screen out the truly valuable content, which is also a serious cause for many people to start to criticize the "watering". However, this article only focuses on development trends, so the total number of these papers will be used as the denominator to analyze some interesting keyword "phenomenons".
Deep learning framework
When it comes to machine learning, an inevitable hot keyword is the deep learning framework. What kind of framework does academics prefer? We have compiled the statistical results of last year and this year, please compare the feelings with the table:
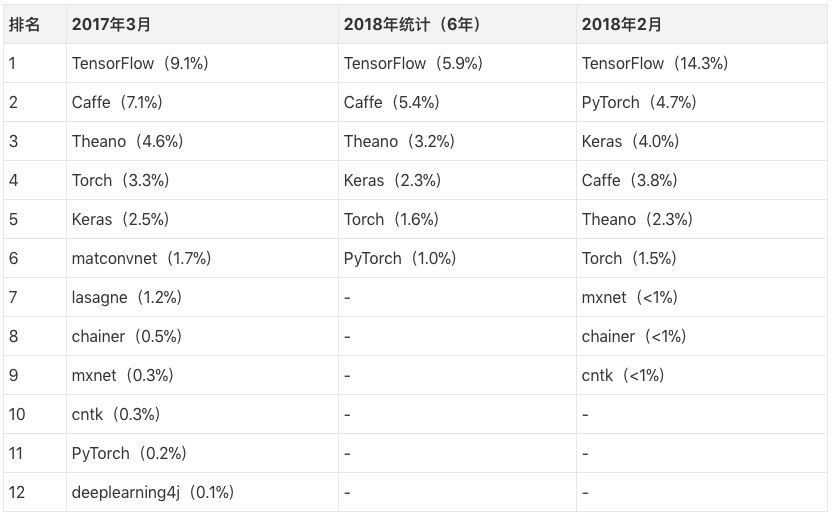
It should be noted that our denominator here is the total number of statistic papers. Take March 2017 as an example. TensorFlow (9.1%) refers to TensorFlow, which was mentioned in the machine learning papers submitted to arxiv in March last year. Of course, this also means that most of the papers of the month did not introduce the framework that they used. But if we assume that the paper points out that the use of the framework follows a fixed random probability, then after a rough estimate, we can guess that about 40% of the labs are using TensorFlow. In February of this year, the proportion of TensorFlow increased to 14.3%, and then the TF is used as the back-end framework. There is no doubt that TensorFlow is indeed the preferred framework for most academics.
Caffe and Theano have accumulated a large number of old users and papers because of their long history. Therefore, their proportion is still outstanding.
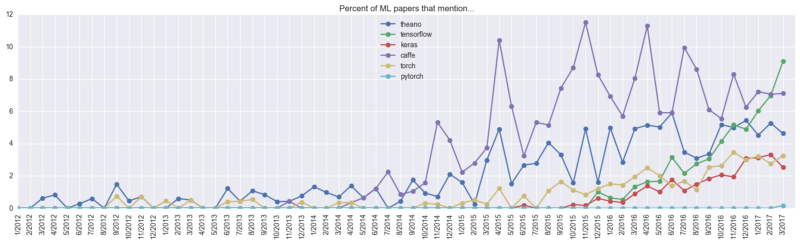
Development of various frameworks before April 2017
In order to more intuitively feel the development trend of each framework, let's take a look at the two pictures of last year and this year. The purple Caffe and the dark blue Theano in the picture above have been well received by the academic community for a long time, and the green TensorFlow has sprung up in 2016. It only surpassed the “predecessors†in one year, and the growth momentum is remarkable. At the time, Andrej Karpathy had predicted that Caffe and Theano's market share would slowly decline, while TensorFlow's growth would slow down. He was more optimistic about PyTorch, which had little sense of existence at the time.
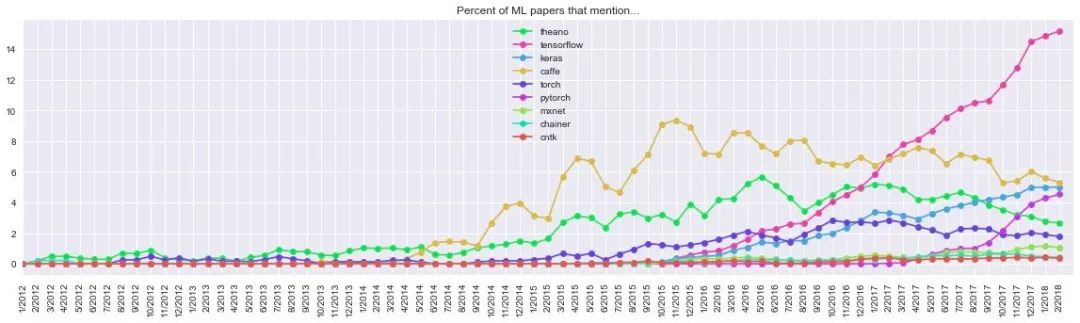
Development of various frameworks before March 2018
Sure enough, the recent chart shows that the pink TensorFlow has experienced two years of growth and has stabilized towards the end of 2017, while the curves of Caffe and Theano have fallen almost simultaneously, and the latter’s share has fallen to fifth place. Caffe, who was struggling in the second place, was also caught up by the "up-and-comers" Keras and PyTorch. The most eye-catching one is PyTorch. This framework, which was less than 0.2% in March 2017, has reached 4.7% in February 2018. Considering the explosive growth of papers in recent years, the prospect of PyTorch can be expected, taking the message under the original twitter. That is:
PyTorch is on fire! (PyTorch wants fire!)
CNN model
CNN was originally designed to solve problems such as image recognition. Of course, its current application is not limited to images and video, but also for time series signals such as audio signals and text data. In dealing with these problems, except for special cases, we usually do not create a new CNN from scratch, but adjust the parameters based on the existing model. So which is the most popular CNN model? Andrej Karpathy did not update the relevant data of the model, so we still rely on last year's data.
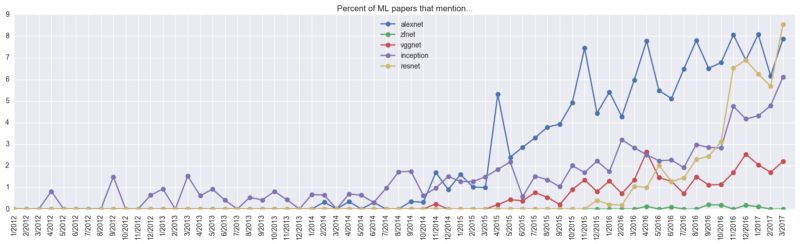
CNN has four classic models: AlexNet, VGGNet, Google Inception Net, and ResNet. From the above picture, we can see that Inception has been outstanding for a long time before the papers about AlexNet began to appear. At the end of 2014, AlexNet ushered in rapid growth and remained stable at a high level for a long time. Just a year later, ResNet also ushered in an outbreak, and by 9% in March 2017, it jumped to the first place.
optimization
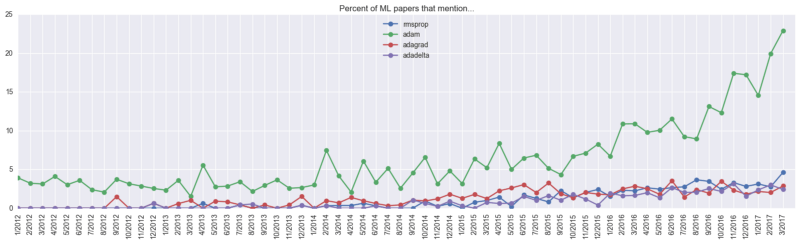
As far as the optimization algorithm is concerned, Adam is the undisputed "head". As of April last year, about 23% of machine learning papers mentioned it. Of course, it is difficult to estimate its actual use ratio: it may be higher than 23%, because some papers do not introduce the optimization algorithm used, most of which even do not mention neural network optimization at all; it may also need to be at 23% On the basis of subtracting 5%, because this keyword is not manually extracted, it is not excluded that Adam is actually a personal name, and as an optimization algorithm, Adam's proposed time is December 2014.
Researchers
Although everyone is enthusiastic about Deep Learning and there are a lot of sought-after expert idols in the industry, are these idols really suitable for everyone? Is the idol you chased a real expert? From the actual citation of the paper, who has a higher "gold content"? Andrej Karpathy also gave us some inspiration from the data.

The top four people from top to bottom are Bengio, Lecun, Hinton, and Schmidhuber. They are recognized as the four most active scholars in deep learning. It can be found that Bengio's appearance in the paper and Hinton go hand in hand, ranking first with 35%, while Hinton ranked second with 30%. But considering that Yoshua Bengio's younger brother, Samy, also has a good track record in machine learning, 35% of this percentage contains some water.
Another person to mention is Jürgen Schmidhuber, the father of LSTM, whose citations are also considerable. Schmidhuber is currently the head of the Swiss artificial intelligence laboratory. Because he likes to study independently, he may not pay much attention to him in the country, but this does not hinder the industry's affirmation. Here is an introduction to his new work One Big Net For Everything. In addition to the title is scary, nearly half of the cited documents are written by him. Interested readers can refer to the brain circuit of the great god.
Hot/cold door tags
Andrej Karpathy also crawled some of the key words in the paper and observed their popularity.
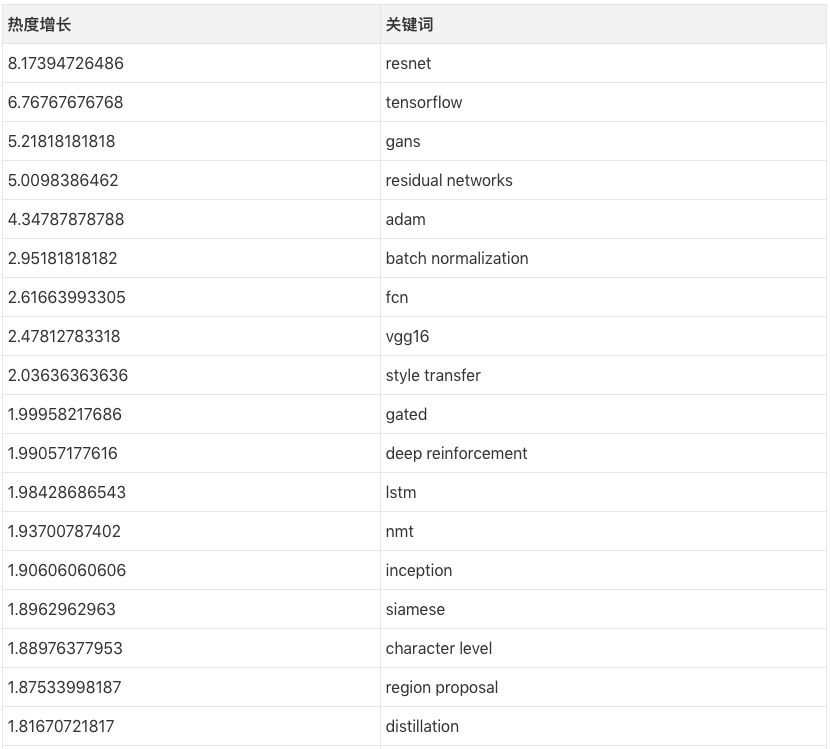

The above values ​​are calculated as follows: taking resnet as an example, its frequency of occurrence was only 1.044% before March 2016, and its frequency of occurrence in March 2017 was 8.53%, so its heat growth was 8.53/1.044~= 8.17. In contrast, last year's hottest paper keywords were ResNets, GANs, Adam, and BatchNorm, and the most popular research areas were style migration, deep reinforcement learning, neuromachine translation, and image generation. The ranking of popular architectures is FCN, LSTM/GRU, conjoined network and code-decoding network.
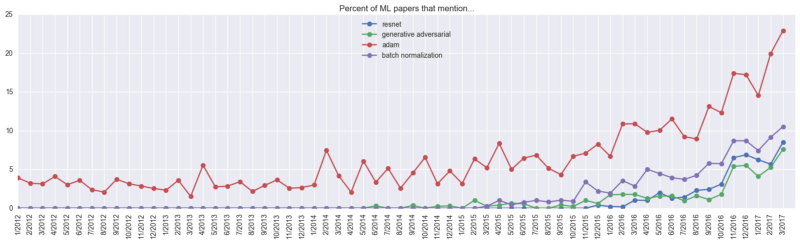
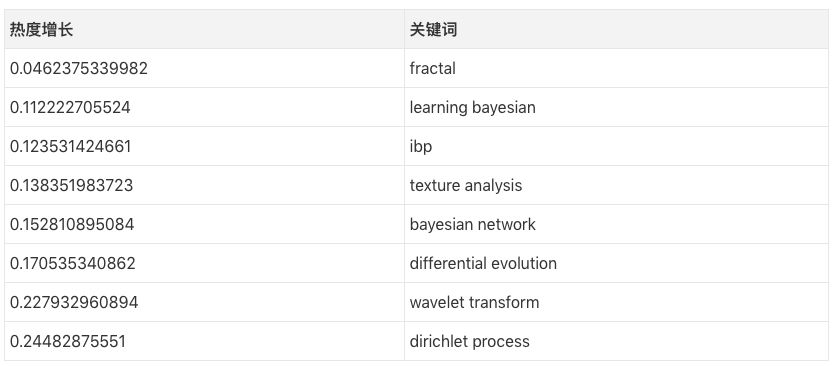
In addition, some of the keywords were thrown into the corner by the researchers "ruthlessly". Although it is not clear what the first-ranked fractal actually refers to, it is estimated to be the content of the Bayesian parameter.
summary
Look at the full text, your "will be based on the full convolutional coding - decoding batch normalization architecture, Adam optimized optimistic processing of ResNet GAN for style migration" how the paper is prepared (English names are all for you to think about it, Called Fully Convolutional Encoder Decoder BatchNorm ResNet GAN applied to Style Transfer, optimized with Adam), this topic does not sound too much outrageous :)
Bilge float alarm,Bilge float alarm price,Bottom floating alarm
Taizhou Jiabo Instrument Technology Co., Ltd. , https://www.taizhoujbcbyq.com