
First, let a kitten lead us into the world of deep learning!

For an input sample, deep learning and machine learning have the same purpose, which is to classify the sample most accurately. It is easy for us to see that this is a cat from the naked eye, because we have accumulated common sense for so many years! But computers are not so clever to tell at a glance. In a computer, an image is made up of pixels.
There may be students who are not very familiar with computer vision. I will briefly introduce that the pixel point is a positive value ranging from 0 to 255, then the size of this point means the brightness of the area corresponding to this point. We can also treat a picture as a three-dimensional array such as [256, 256, 3] where 256 represents the length and width of the picture respectively, and the last 3 is the color channel of the picture. It doesn’t matter if you don’t know what the channel is. Let us know for the time being that the picture is composed of a matrix!
This matrix looks like this
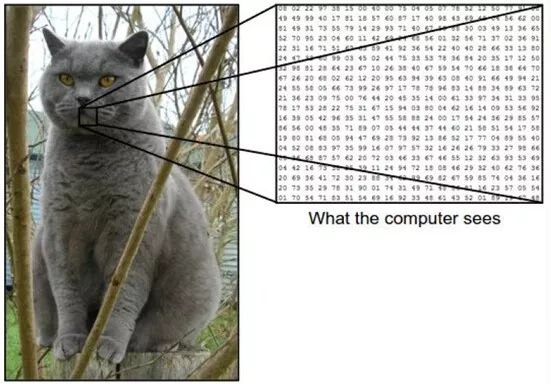
So what are the challenges we face?
What we have to face is not just such a cute kitten squatting in front of us. There are many possibilities in practice, such as light intensity, degree of occlusion, angle, etc. These have become one of our deep learning tasks. Great challenge.
These aliens are the challenge we face

The core and most basic problem to be solved by deep learning is the classification task. It is also the best starting point for our understanding of deep learning.
Routine routines for classification problems

The routine routines of a classification task can be roughly divided into three points:
1. Collect data and assign labels:
That is, we are going to make a training set, including the two parts of data label. Don’t underestimate the data collection. This is actually very troublesome. It is difficult to train an excellent model without suitable data. Both quantities are very important. One It is quality and quantity. For our deep learning, quantity is very important. Basically, it must be based on ten thousand.
2. Training a classifier: This step can be said to be a very core step. The effect of the classifier determines the effect of our final application. The effect of deep learning is better than that of traditional machine learning in some areas such as computer vision. The main reason is that the classifier trained by deep learning is more powerful. In this lesson, we will only briefly introduce it. The dry goods are still in the back.
3. Test and evaluation: A good classifier cannot be achieved through a large amount of data and a powerful model structure. After training the classifier, a more important point is that we have to test and evaluate, such as accuracy, recall and other metrics. We need to repeatedly adjust the model parameters through these indicators until we get the best model. Whether it is machine learning or deep learning, these three steps are inseparable. With such a process, let’s take a look at how traditional machine learning algorithms are. For classification tasks.

This is the database. Simply put, this database has 10 categories of labels, that is, there are 10 categories. The next thing to do is to train a classification model.
Many of my classmates may say that I am a very second person, but in order to better express the students who are just getting started (pit) more intuitively, let's simply enjoy it.
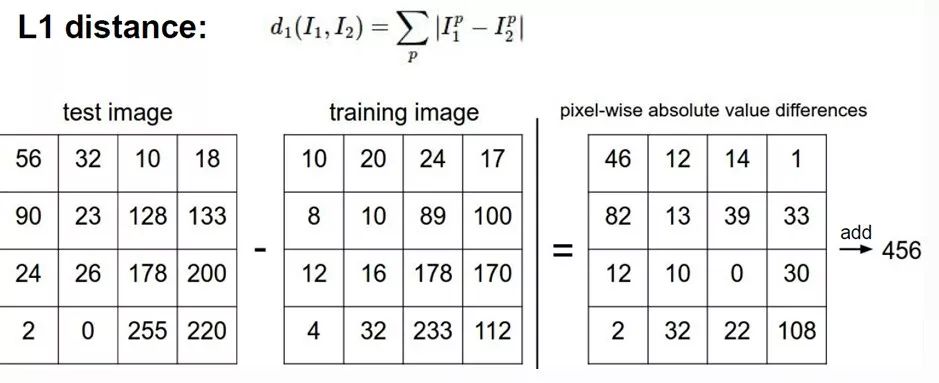
Use the matrix formed by the pixels of each picture to calculate the data samples with the smallest difference from its pixels. Although the method is very two, it is also a simple K-nearest neighbor problem. We calculate the distance between the input and all the samples in the training set through the L1 distance of the pixel (see the formula) and then find the smallest K, the input The category of the sample is the voting sum of the K ones.
What I want to emphasize here is that I am not using this approach to talk about a classification process, but to let everyone see what we need in our traditional approach. The parameters we need when doing classification are the size of K in K’s nearest neighbors. We also need to choose the distance formula, which is the choice of L. This is just the least parameter choice. For more complex models, we need to choose the parameters. More. Different parameter selections can be said to have a great impact on the final result. This is a headache for traditional machine learning algorithms. Many things require us to keep trying. Then one of the powerful aspects of deep learning is that we don't need to set many such hyperparameters.
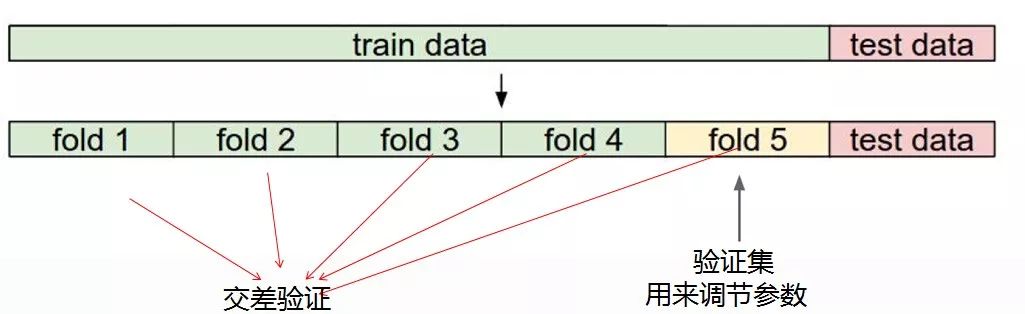
Next, let's emphasize the above picture. The purpose of this is that many students do not have much machine learning and actual combat foundation, and we need to give everyone a general idea of ​​the division of the data set.
Our data preparation before training the model is to divide the entire data into two parts, one is the training data and the other is the test data. Theoretically speaking, test data is very precious. We can only use test data to evaluate at the end, and never allow test data to appear during the training process.
There is also that we have to split most of the training data into several small parts, such as 5 small parts. The purpose of this is that we also need a verification set. The meaning of the verification set is that we must continue to train the model. Make a process of self-testing the effect of the model, such as using 4 small copies as training data and another small copy as verification data. There is another point of knowledge that I want to emphasize. When we actually train the model, we use cross-check verification. What is cross-check? That is, we will take these 4 as training this time, and next time we will take the other 4 as training, so as to ensure that our training model is more reliable!
Based on ergonomic design principles. Raise the height of the display screen and stretch the distance between the eyes and the screen, so that notebook users will no longer be troubled by sub-health occupational diseases such as cervical pain and visual fatigue caused by long-term use of the notebook, and restore the normal state of easy office work.
Shenzhen Chengrong Technology Co.ltd is a high-quality enterprise specializing in metal stamping and CNC production for 12 years. The company mainly aims at the R&D, production and sales of Notebook Laptop Stands and Mobile Phone Stands. From the mold design and processing to machining and product surface oxidation, spraying treatment etc ,integration can fully meet the various processing needs of customers. Have a complete and scientific quality management system, strength and product quality are recognized and trusted by the industry, to meet changing economic and social needs .

Portable Laptop Stand Foldable,Lightweight Portable Laptop Stand,Portable Laptop Computer Stand,Portable Laptop Stand for Travel
Shenzhen ChengRong Technology Co.,Ltd. , https://www.dglaptopstandsupplier.com