
Figure 2 Encoding, transmission, and human ear listening
2.1 According to the auditory domain, the audible signal is encoded by the human ear. The frequency and sound pressure level have a certain range. The normal frequency range is about 20Hz~20kHz, while the sound pressure level range is It is described as the threshold curve. This means that the signal at the corresponding frequency below this curve is inaudible.
Figure 16 MPEG-2 audio mixed surround sound compatibility As shown in Figure 3, for signal A, because its sound pressure level exceeds the sound pressure level value of the hearing threshold curve, it can cause the sound vibration of the human ear. It means to hear the A signal. For the B signal, the sound pressure level is below the hearing threshold curve. Although it exists objectively, the human ear is inaudible. Therefore, similar signals can be removed to reduce the audio data rate.
2.2 According to the masking effect, only the masking signal with strong amplitude is encoded. The human ear can distinguish the slight sound in the silent environment, but in the noisy environment, the same sound is submerged and cannot be heard. This phenomenon in which another sound is to be heard by raising the sound pressure level due to the presence of one sound is called an auditory masking effect.
As shown in Figure 4, although the sound pressure levels of the B and C signals have exceeded the range of the hearing threshold curve, the human ear can already hear the presence of the B and C signals, but due to the presence of the A signal, the C is forwarded by the forward masking. The signal is submerged, and the B signal is submerged by the back masking, so that only the A signal is finally reached by the human ear. Therefore, similar B and C signals can be removed to reduce the audio data rate.
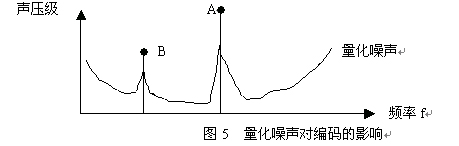
2.3 Quantization noise makes it unnecessary to fully encode the original signal similar to the hearing threshold curve of the human ear. Since the digital signal has quantization noise, as shown in Fig. 5, for signals A and B, it is not necessary to use A and B signals. By encoding the full amplitude, the same audible effect can be achieved by encoding the difference between the A and B signals and the quantization noise. Therefore, the actual quantization amplitude can be greatly reduced and the data rate can be reduced during the encoding process.
2.4 Optimization by sub-band segmentation, coding In the traditional coding process, the entire frequency band is used as the operation object, and each signal is quantized by the same bit allocation. In fact, due to the existence of the auditory curve and other factors, a smaller number of signals can be allocated with fewer bits, so the entire frequency band is divided into multiple sub-bands, and then the signals of each sub-band are independently encoded. Thereby the bit allocation in each sub-band can be adapted according to the signal itself.
As shown in the ABCD four signals, if the entire frequency band is encoded, it is redundant to allocate 16 bits for the D signal. Therefore, if the ABCD is placed in a different sub-band, the sub-bands can be respectively located. The number of bits that are most suitable for use is allocated to the signal to be encoded, thereby reducing the data rate, and if the sub-band resolution for segmentation is higher, that is, the band of the sub-band is relatively narrower, the number of bits allocated in the sub-band The more precise, the lower the bit rate.
2.5 Different Implementations There are various coding schemes and implementation methods in the field of digital audio coding. In order to let everyone have a more complete understanding of this, in this paper, only the typical coding methods that are currently popular are available. Make an introduction. No matter which way it is implemented, the basic coding idea block diagrams are similar, as shown in Figure 7. For PCM audio signals in each audio channel, they are first mapped to the frequency domain. This time-domain to frequency domain mapping can be done through subband filters (eg MPEG Layers I, II, DTS). Or by transforming filter banks (such as AC-3, MPEG AAC). The biggest difference between the two methods is the difference in frequency resolution in the filter bank.
The audio sample block in each channel first calculates the masking threshold based on the psychoacoustic model, and then uses the calculated masking threshold to determine how to allocate the bits in the common bit region to signals in different frequency ranges. For example, MPEG Layers I, II, DTS; or the calculated masking threshold to determine which frequency range of quantization noise can be introduced without removing, such as AC-3, MPEG AAC.
It is then quantized according to the time domain expression of the audio signal, followed by squelch encoding (eg MPEG Layers I, II, DTS, MPEG AAC). Finally, the control parameters and the auxiliary data are interleaved to generate an encoded data stream. The decoding process first demultiplexes the encoded data stream, then dequantizes the audio data through control parameters transmitted in the bit stream, or obtains an audio signal (such as AC-3) through inverse calculation of psychoacoustic model parameters, and finally The obtained audio signal is inversely transformed from the frequency domain to the time domain to complete the decoding process.
In addition, multi-channel digital audio coding technology also makes full use of the correlation between channels and binaural hearing effects to further remove the redundancy and irrelevance between channels. One of the most common methods for removing correlation between channels is the M/S mode, in which the spectra of two independent channels are added and subtracted, depending on the correlation of the two channels. It is decided whether to transmit the //difference signal or the original signal.
Since the human ear's sound localization for frequencies exceeding 2-3 kHz is mainly achieved by inner ear density difference (IID), in order to further reduce the data rate, signals in the respective channels whose frequencies exceed the agreed threshold are combined and transmitted. This technique is used in MPEG Layers I, II, III for intensity stereo coding; it is used in AC-3 for multichannel coding of two channels or coupled channels. In MPEG AAC, both intensity stereo coding and multi-channel coding can be achieved.
1, Dolby Digital AC-3 codec compression process
AC-3 was first applied in the 1991 film "Batman Returns". Its application not only has a place in the film industry, but it has also been defined by digital TV and DVD video in North America as its digital audio implementation specification. The AC-2 and AC-3 we are familiar with are all developed from two channels, namely Dolby Digital. For digital audio signals, the digital compression algorithm is applied to reduce the amount of digital information needed to correctly reproduce the original pulse code modulation (PCM) samples, resulting in a digitally compressed representation of the original signal.
3.1 AC-3 encoding process
The AC-3 encoder accepts PCM audio and produces a corresponding AC-3 digital stream. At the time of encoding, the AC-3 algorithm achieves a high coding gain (ratio of input code rate to output code rate) by coarsely quantizing the frequency domain expression of the audio signal. As shown in Figure 8.
The first step in the encoding process is to transform the audio expression from a sequence of PCM time samples into a sequence of frequency coefficient sample blocks. This is done in the analysis filter. The mutually overlapping sample blocks of 512 time samples are multiplied by the time window and transformed into the frequency domain. Each PCM input sample will be expressed in two successive transform sample blocks due to mutually overlapping sample blocks. The frequency domain expression can be taken as two, so that each sample block contains 256 frequency coefficients. These individual frequency coefficients are expressed in binary exponential notation as a binary exponent and a mantissa. This set of indices is encoded as a coarse expression of the signal spectrum called the spectral envelope. The core bit assignment routine uses this spectral envelope to determine how many bits need to be encoded for each individual mantissa. The spectral envelope and the mantissa of the roughly quantized 6 audio sample blocks are formatted into an AC-3 data frame (FRAME). The AC-3 digital stream is a sequence of AC-3 data frames.
In the actual AC-3 encoder, the following functions are also included:
A header with a data frame containing information synchronized with the encoded digital stream and decoded (bit rate, sampling rate, number of encoded channels, etc.).
l Insert the error detection codeword so that the decoder can check whether the received data frame has a bit error.
l The spectral resolution of the analysis filter bank can be dynamically changed to match the time domain/frequency domain characteristics of each audio sample block.
The spectral envelope can be encoded with variable time/frequency resolution.
l More complex bit assignments can be implemented and some parameters of the core bit assignment routine can be modified to produce more optimized bit assignments.
Some channels can be coupled together at high frequencies to achieve higher coding gains when operating at lower bit rates.
In the two-channel mode, the process of resetting the matrix can be selectively implemented to provide additional coding gain, and a matrix surround decoder can be used when decoding the signals of the two channels, and improved results can be obtained. Development began 85 years later, including the well-known Eureka 147 DAB (Eureka 147 Digital Audio Broadcasting) and DVB. Evolving digital modulation methods and encoding algorithms provide a more efficient way to transmit and store digital audio broadcasts, enabling the transmission of more audio signals with better channel counts at lower bit rates in a limited bandwidth. may. These new technologies, which are at the core, are also fully utilized in the development of digital audio broadcasting systems. In the past, stereo broadcasting played a leading role, and now with the increasing use of multi-channel digital audio systems, digital audio broadcasting has begun to accept and develop relevant audio standards. In Eureka 147 DAB and DVB, an extension of multi-channel digital audio has been included.
7.1
The Eureka 147 DAB International Agreement was established in 1986 by 16 European member organizations to develop standards for digital audio broadcasting standards. Later, some new organizations joined the agreement and formed the first DAB standard in 1995. In the same year, worldwide DAB forums were also established. Their goal is to promote the implementation of digital audio broadcasting based on Eureka 147 DAB by more organizations around the world.
The Eureka 147 DAB system is designed to replace the current FM broadcast service. It uses COFDM (Coded Orthogonal Frequency Division Multiplexing) to better perform mobile reception and overcome multipath effects. The carrier uses DQPSK (the difference is positive). Interphase shift keying is used for modulation, and channel coding is performed by convolutional coding to meet the need for adjustable bit rate.
The Eureka 147 DAB system uses a spectrum bandwidth of 1.536MHz to transmit data up to 1.5Mb/s, so for multiple channels, such as 6 channels, the data rate of each channel is no more than 256kb/ s. How the channels are allocated and used is compromised based on the number of programs/data services and audio quality. Since the development of the early Eureka 147 DAB source code did not reflect the latest developments in the technology, and because of historical reasons and DAB standards were developed by Europe, and Europe has long used MPEG technology, considering compatibility issues, DAB system The intermediate audio coding system uses the MPEG Layer II coding scheme. Can't say that there is something wrong with the MPEG Layer II encoding scheme, but if we look at the latest developments in current multichannel digital audio systems, it's not hard to see that there are more and better solutions that can be adopted, such as improving sound quality. In the DTS system, the MPEG AAC system can be used to increase the number of channels.
7.2
The DVB project was established in 1993 by more than 220 world organizations. These world organizations include broadcasters, manufacturers, network managers, and organizations that are committed to developing digital television standards. The earliest DVB service began in Europe, and now the DVB standard is not only a European digital TV standard, but it also extends to Asia, Africa, the Americas and Australia, becoming one of the selection criteria for digital TV in these regions. The United States that uses this is the ATSC system.
Three subsystems are specified in the DVB standard: DVB-S (satellite), DVB-C (wired) and DVB-T (terrestrial) systems. The DVB-S system is a single-carrier system and is the earliest implemented DVB standard. It is based on quadrature phase shift keying (QPSK) modulation and channel coding (convolution coding and Reed-Solomon block coding). On the above, the typical code rate is about 40Mb/s. The DVB-C system is based on the DVB-S system, except that it uses QAM (Quadrature Amplitude Modulation) modulation instead of the QPSK modulation method used in DVB-S. If 64-point QAM modulation is used in DVB-C, it is possible to transmit 38.5 Mb/s of data in a bandwidth of 8 MHz. The difference between the DVB-T system and the above two is that the modulation method of COFDM is adopted, and the channel coding is basically the same as the former two. In the DVB-T system, it is possible to transmit 19.35 Mb/s of data in a bandwidth of 7 MHz.
The source code for the DVB system is based on the MPEG-2 video and MPEG-2 system standards. A stereo multi-channel digital audio system is also available in DVB. Also for historical and other reasons, the MPEG Layer II multi-channel digital audio system is still used in the DVB audio part. In the DVB standard, it is also stipulated that it can adopt more flexibility and higher quality than MPEG Layer II. The multi-channel digital audio system of the MC system acts as an audio part of DVB.
In short, with the continuous development of digital broadcasting, I believe that these mature technologies will have their own use.
8. Conclusion In this paper, we mainly discuss several popular multi-channel digital audio systems, and also make a detailed analysis and comparison of the main techniques of the coding methods they use. With the continuous development of storage media and transmission bandwidth technology, it is believed that multi-channel digital audio systems will gradually replace traditional audio systems such as CD format; audio coding and transmission schemes also applied to multi-channel digital audio systems will continue to Update and develop. More channel implementations and higher quality audio system implementations are possible, such as the coding scheme in the newly established DVD-Audio audio technology that goes far beyond the PCM audio method.
All in all, we believe that in the future development of digital broadcasting, whether it is DVB, DAB, digital video, audio broadcasting, or ATSC digital TV system, etc., will be limited by bandwidth (relatively speaking) and can provide higher Multi-channel digital audio system with quality and more channels.
This article refers to the address: http://
3. 2 AC-3 decoding process The decoding process is basically the inverse of the encoding process. The decoder must synchronize with the encoded digital stream, check for errors, and de-format different types of data, such as the encoded spectral envelope and quantized mantissa. Run the bit assignment routine and use the result to solve the unpack and dequantization of the mantissa. The spectral envelope is decoded to produce individual indices. Each index and mantissa is transformed back into the time domain to become a decoded PCM time sample.
In the actual AC-3 decoder, the following functions are also included:
l If a data error is detected, you can use error code to mask or squelch.
Those channels with high frequency content coupled together must be decoupled.
l The process of removing the matrix (in 2-channel mode) must be performed whenever the channel of the matrix has been reset.
The resolution of the integrated filter bank must be dynamically changed, in the same way as the encoder analysis filter bank used in the encoding process.
3. 3 Dolby Digital AC-3 encoded data format The encoding of the Dolby Digital AC-3 encoder allows the original data PCM signal to be encoded into a Dolby Digital AC-3 audio data stream. An AC-3 serial encoded audio data stream consists of a sequence of sync frames. As shown in Figure 10.

As can be seen from the figure, each sync frame contains six encoded audio sample blocks (AB) each of which represents 256 new audio samples. In the header of the synchronization information (SI) at the beginning of each synchronization frame, information necessary for obtaining synchronization and maintaining synchronization is included. Following the SI is the header of the Digital Stream Information (BSI); it contains various parameters describing the services of the encoded data stream. The encoded audio sample block is followed by an auxiliary data (AUX) field. At the end of each sync frame is an error check field containing a CRC word for error detection. An additional CRC word is located in the SI header for selection.
Each block of AB0~AB5 represents a coding channel, which can be independently decoded, and the size of the block can be adjusted, but the total data amount is unchanged. There are also two unmarked CRCs in the figure, where the first one is at 5/8 of the frame and the other is at frame not. The reason for this arrangement is that the decoder's RAM requirement can be reduced, so that the decoder does not have to completely receive a frame to decode the audio data, but is divided into two parts for decoding.
3.4 Dolby Digital AC-3 Compatibility Since AB0~AB5 in the synchronization structure in the AC-3 bitstream are independently decoded, these coded signals can be reconstructed into the desired output signal, ie the downlink compatibility of the output. .
In many playback systems, the number of speakers cannot match the number of encoded audio channels. In order to reproduce the complete audio program you need to mix down. In frame synchronization, audio data of six independent channels are recorded in AB0~AB5. According to the arrangement of AC-3 playback, we call it L, R, C, Ls, Rs, LFE. Generally used in the process of downmixing, the audio signal recorded by the bass enhanced LFE channel is mainly used to render the atmosphere, so when mixing down, only L, R, C, Ls, Rs are used. It can be seen from the figure that the encoded AC-3 data stream can be directly transmitted and decoded by the decoder into 5.1 channel audio information for playback, or can be downmixed into two channel signals, and then obtained by different decoders. Different playback modes. In the case of a single surround channel (n/1 mode), S is referred to as a single surround channel. As can be seen from the figure, there are two types of downmixing: downmixing into stereo pairs of Lt, Rt matrix surround coding;
Mix down to the usual stereo signals Lo, Ro. The downmixed stereo signals (Lo, Ro or Lt, Rt) can be further downmixed into a mono M, simply by adding the two channels. If you mix Lt, Rt down to mono, the surround information will be lost. When it is desired to require a mono signal, it is preferable to mix Lo and Ro downwards.
The general 3/2 downmix equation for Lo and Ro stereo signals is:
Lo=1.0'L+clev'C+slev'Ls;
Ro=1.0'R+clev'C+slev'Rs;
If Lo, Ro are then combined into a mono signal playback, the effective downmix equation is:
M=1.0′L+2.0′clev′C+1.0′R+slev′Ls+slev′Rs;
If only a single surround channel S (3/1 mode) appears, the downmix equation is:
Lo=1.0'L+clev'C+0.7'slev'S;
Ro=1.0'R+clev'C+0.7'slev'S;
M=1.0′L+2.0′clev′C+1.0′R+1.4′slev′S;
Where clev and slev represent the central channel mixed sound level coefficient and the surround channel mixed sound level coefficient, respectively, and the corresponding values ​​are indicated by the Cmixlev and Surmixlev bit fields in the BSI data.
The general 3/2 downmix equation for Lt, Rt stereo signals is:
Lt=1.0'L+0.707'C-0.707'Ls-0.707'Rs;
Rt=1.0'R+0.707'C+0.707'Ls+0.707'Rs;
If only a single surround channel S (3/1 mode) appears, the downmix equation is:
Lt = 1.0'L + 0.707 'C-0.707'S;
Rt = 1.0 'R + 0.707 'C + 0.707 'S;
After different allocation and matrix recombination of the audio signals of the independent channels, the backward compatibility of the AC-3 data stream is realized, that is, the Dolby Digital 5.1 channel can be obtained through different decoders and decoding matrix modes. Surround, stereo, Dolby Prologic, Mono, and Dolby Virtual Surround. The biggest difference between Lo and Ro and Lt and Rt is that Lt and Rt are all recorded L, R and surround sound information. After matrix re-extraction, surround sound information can be obtained, while Lo and Ro increase surround sound information. Surround signal information cannot be reproduced in a stereo signal.
4, MPEG-2 multi-channel codec process
The MPEG-2 perceptual coding system makes full use of the masking effect and the Haas effect in psychoacoustics, and uses the compression coding technique to effectively remove the uncorrelated and redundant components of the original audio signal without affecting the auditory threshold of the human ear. And the quality of the listening effect, the audio signal is compressed.
4.1 Basic Structure of the MPEG Audio Subband Encoder The subband audio encoder continuously analyzes the audio input signal. The masking threshold is dynamically determined by a psychoacoustic model, ie excess noise below the masking threshold is not audible to the human auditory system. The information generated by the psychoacoustic model is fed to a bit allocation module whose task is to distribute the bits available for each channel in the spectrum over an optimized manner. The input signal is also split into a series of frequency bands called sub-bands in parallel with the above process. Each sub-band signal is re-quantized after being scaled, and the quantization noise introduced by the quantization coding process cannot exceed the masked threshold of the determined corresponding sub-band. Therefore, the quantization noise spectrum is dynamically adaptive to the signal spectrum. The "scale factor" and the information about the quantizer used by each subband are transmitted along with the encoded subband samples.
The decoder can decode the code stream without knowing how the encoder determines the information needed for the encoding. This can reduce the complexity of the decoder and provide great flexibility for encoder selection and decoder development. As new results are obtained in psychoacoustic research, higher efficiency and higher performance encoders can be applied with full compatibility with all existing decoders. This flexibility is now a successful example, and the performance of the highest-tech encoders now exceeds the early encoders used in the standardization process.
4.2 layer
The MPEG audio standard includes three different algorithms called layers. The higher the number of layers, the higher the corresponding achievable compression ratio, and the higher the complexity, delay, and sensitivity to transmission errors. Layer II is specifically optimized for broadcast applications. It uses subband filtering with 32 equal-width subband partitioning, adaptive bit allocation and block companding. Mono has a bit rate range of 32-192 kbps and stereo is 64-384 kbps.
It performs very well in 256 kbps and 192 kbps related stereo conditions. Performance at 128 kbps (stereo) is still acceptable in many applications.
4.3 MPEG-2 expansion in multi-channel audio
ITU-R Working Group TG10-1 has worked on recommendations for multichannel sound systems. The main result of this work is the recommendation BS.775, which states that an appropriate multi-channel sound configuration should contain five channels representing the left, center, right, left surround, and right surround channels. If a low frequency enhancement channel (LFE) is used as an option, the configuration is referred to as "5.1". The five-channel configuration can also be expressed as '3/2', ie three front channels and two surround (post) channels.
MPEG has recognized the need to increase the multi-channel capabilities of audio standards in accordance with ITU-R Recommendation 775.
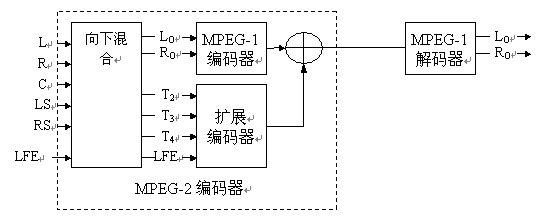
This was done in the second phase, which resulted in the MPEG-2 audio standard. The expansion in multi-channel sound supports the transmission of five input channels, low-frequency enhancement channels, and seven narration channels in one stream. This extension is compatible with MPEG-1 for forward and backward compatibility. Forward compatibility means that the multichannel decoder can correctly decode the stereo stream. Backward compatibility means that a standard stereo decoder can output a compatible stereo signal when decoding a multi-channel stream.
This is achieved in a truly scalable way. At the encoder side, the five input channels are downmixed into one compatible stereo signal. The compatible stereo signal is encoded in accordance with the MPEG-1 standard. All of the information used to recover the original five channels at the decoder side is placed in the additional data area of ​​MPEG-1, which is ignored by the MPEG-1 decoder. This additional information is transmitted in the information channels T2, T3 and T4 and the LFE channels, which typically contain the center, left surround and right surround channels. The MPEG-2 multi-channel decoder decodes not only the MPEG-1 portion of the stream but also the additional information channels T2, T3, T4 and LFE. Based on this information, it can restore the original 5.1 channel sound.
When the same code stream is fed to the MPEG-1 decoder, the decoder will only decode the MPEG-1 portion of the code stream, ignoring all additional multi-channel information. This will output the two channels produced by downmixing in the MPEG-2 encoder. This approach achieves compatibility with existing two-channel decoders. Perhaps more importantly, this scalable approach allows low-cost two-channel decoders to be used even in multi-channel services. Considering all other coding strategies used, the two-channel decoder in multi-channel services is essentially a multi-channel decoder that decodes all channels and produces a two-channel downmix signal in the decoder. . As shown in Figure 14.
This standard is very flexible insofar as it contains different techniques that can be used by the encoder to further improve the audio quality.
4.4 Directional Logic Compatibility If the source material has been encoded in surround sound (such as Dolby surround sound), the broadcaster may wish to broadcast it directly to the listener. One option is to broadcast the material directly in 2/0 (stereo only) mode. The surround coder mainly adds the center channel signals to the left and right channel signals in phase, and adds the surround channel signals to the left and right channel signals, respectively. In order to properly decode this information, the codec must maintain the amplitude and phase relationship between the left and right channels. This is guaranteed in MPEG encoding by limiting the intensity of stereo coding that can only be used over a frequency range above 8 kHz, since surround sound coding uses surround channel information only in the range below 7 kHz. As shown in Figure 15.

Figure 15 Broadcasting surround sound material using MPEG-1 audio
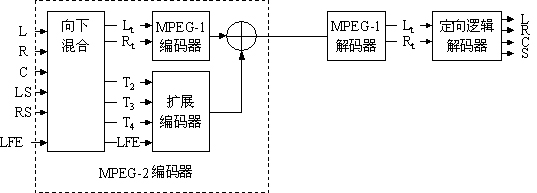
When multi-channel information is transmitted, compatibility with existing (patented) surround sound decoders can be achieved by several means. Multichannel encoders use a surround compatible matrix when working. This allows the stereo decoder to receive the surround encoded signal.
It can optionally be transferred to a surround decoder. A complete multi-channel decoder will re-convert all signals to achieve the original multi-channel performance. This mode is supported by the MPEG-2 multichannel syntax and is also supported by the DVB specification. As shown in Figure 16.
4.5 MPEG-2 expansion in terms of low sampling rate In addition to the expansion in multi-channel, MPEG-2 audio also includes an extension of MPEG-1 audio in terms of low sampling rate. The purpose of this extension is to obtain improved spectral resolution in a simple manner. By halving the sample rate, the frequency resolution is doubled, but the time resolution is degraded by a factor of two. This allows many steady-state signals to achieve better quality, while for some signals that are time-critically demanding, the quality is degraded. The use of the half sampling rate is represented in the code stream by setting a bit in each frame header, that is, the ID position to "0". Moreover, the available rate tables have also been modified to provide more choices at low bit rate conditions, and the quantizers available for each sub-band have also been modified to accommodate higher frequency resolutions.
5, advanced audio coding (Advanced Audio Coding-AAC)
MPEG AAC (Advanced Audio Coding) became an ISO/IEC standard in 1997 (see ISO/IEC 13818). AAC is composed of a coding algorithm for time domain to frequency domain mapping in the newly established MPEG-4 standard. From the perspective of improving efficiency, AAC abandoned the backward compatibility with the original MPEG-1 decoder, which is why the algorithm was called NBC at the beginning.
5.1 Main features of AAC
AAC can support any number of audio channel combinations between 1 and 48 channels, including 15 low-frequency effects channels, dubbing/multi-voice channels, and 15 channels of data. It can transmit 16 sets of programs at the same time, and the audio and data structure of each set can be arbitrarily specified. At a bit rate of 64 kbps/channel, AAC provides high sound quality.
Depending on the application, AAC offers three types of profiles: Main Profile, Low Complexity Profile, Scaleable Sampling Rate (SSR Profile). ). Therefore, it can be applied in a wide range.
5.2 AAC algorithm structure To improve audio coding efficiency, AAC uses many advanced technologies such as Huffman coding, correlated stereo, channel coupling, inverse adaptive prediction, time domain noise shaping, modified discrete cosine transform (MDCT), and Hybrid filter banks, etc.
Among them, compared with the filter bank used in MPEG layer III, the filter group considers the compatibility problem when selecting the filter in the layer III algorithm, so it has inherent structural defects; and AAC directly adopts MDCT transform filtering. At the same time, AAC increased the window length from 1152 to 2048, making MDCT better than the original filter bank.
Time Domain Noise Shaping (TNS) technology is a novel technique in time domain/frequency domain coding. It uses the results of adaptive prediction in the frequency domain to shape the distribution of quantization noise in the time domain. By using TNS technology, the quality of voice signals in special environments can be significantly improved.
Backward adaptive prediction is a technology established in the field of speech signal coding systems. It primarily takes advantage of the predictability of a particular form of audio signal.
In the quantization process, a given code rate can be more effectively utilized by more precise control of the quantization precision. When the code stream is multiplexed, the redundancy is minimized by entropy encoding the information that must be transmitted.
Through the use of the above various coding techniques and the adoption of a variable code stream structure, the AAC coding algorithm is greatly optimized, and it also provides the possibility to further improve the coding efficiency in the future.
In fact, among the three types of AAC coding, the use of various coding techniques is also different, that is, the complexity of the three types of algorithms is different. This difference considers the algorithm complexity at both ends of the encoding and decoding. For example, backward adaptive prediction accounts for about 45% of the amount of decoding operations, and this technique is not used in both LC and SSR types. In addition, in the LC type, the length of the TNS filter is limited to 12 coefficients, but still maintains the 18 KHz bandwidth; in the SSR type, the TNS uses only 12 coefficients, and the bandwidth is limited to 6 KHz, and the type There is also no channel coupling technique, and the structure and gain control of the hybrid filter bank are also different from the other two types.
AAC can provide higher quality audio information at low data rates, such as better performance at 64kb/s per channel.
AAC's current applications are mainly used for digital audio broadcasting in Japan and IBOC (in-band co-frequency technology) in the United States.
6. Coherent acoustic coding for DTS
The digital audio compression algorithm used in the DTS system, coherent acoustic coding, is mainly used to improve the audio quality of the playback of the civilian audio playback device, and the audio playback quality can exceed the quality of the original CD record. At the same time, through the use of more speakers, the listener can feel the sound effects that ordinary stereo can't achieve. So the overall goal is to bring the audience into the real world of sound and multi-channel surround sound.
A coherent acoustic encoder is a perceptual, optimized, difference molecular band audio encoder that uses a variety of techniques to compress audio data. This will be described in detail below. Overall, the implementation of the encoder and decoder is asymmetrical. In theory, the encoder can be designed very complicated, but in fact, the encoder 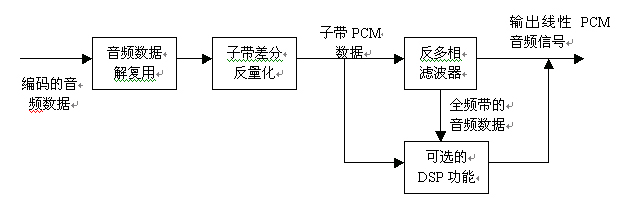
Figure 19 Coherent Acoustic Decoder Flowchart The second step is to inverse quantize the differential signal in the subband to obtain the subband PCM signal by the auxiliary information command transmitted in each subband. These sub-band PCM signals obtained by inverse quantization are subjected to inverse filtering processing to obtain a full-band time domain PCM signal for each channel. In the decoder, there is no program for the adjustment of audio quality.
An optional DSP function module is included in the decoder, which is mainly used for user programming. It allows sub-band or full-band PCM signals to be processed in a single channel or in all channels. These functions include upper matrix transformation, lower matrix transformation, dynamic range control, and delay adjustment between channels.
6.3
The DTS system was first used in movie applications. In the 1993 film "Jurassic Park" (Jurassic Park), instead of using AC-3, a DTS multichannel digital audio system was used. The audio data in the DTS system is stored on a CD-ROM, instead of recording the sound on the film, but the time code for synchronizing the CD-ROM audio information on the film is recorded on the film. Time code to play CD-ROM synchronously. Since CD-ROMs have greater capacity and more reliable reliability than movie film tracks, they provide higher quality multi-channel audio information at a 4:1 compression ratio. For AC-3, the typical compression ratio is 12:1.éšç€åº”用的普åŠï¼ŒDTS系统åˆæ出一ç§ä½Žæ•°æ®çŽ‡ç‰ˆæœ¬ï¼Œå…¶å‚数规范如下:
音频声é“的个数DTS=1——10.1
FsDTS=8——192kHz
RDTS=16——24bit
BDTS=32——6144kb/s
æ•°æ®å¸§å¤§å°DTS=512æ ·æœ¬åœ¨ä½Žæ•°æ®çŽ‡ç‰ˆæœ¬ä¸ï¼Œç”±0到24kHzçš„32个å带的频率,通过一个512抽头的多相æ£äº¤é•œè±¡æ»¤æ³¢å™¨ï¼ˆPQMF)æ¥å®žçŽ°ä»Žæ—¶åŸŸåˆ°é¢‘åŸŸçš„æ˜ å°„ã€‚å¦å¤–8ä¸ªé™„åŠ çš„å带覆盖了24kHz到48kHz之间频率范围,2ä¸ªé™„åŠ çš„å带覆盖了48 kHz到96 kHz之间的频率范围。为了进一æ¥å‡å°å†—余度,采用了å‰å‘自适应线性预测,åŒæ—¶å¿ƒç†å£°å¦æ¨¡åž‹ç”¨æ¥å¯¹ä¿¡å·è¿›è¡Œé¢„测,在é‡åŒ–过程ä¸ä½¿ç”¨äº†æ ‡åº¦é‡åŒ–和矢é‡é‡åŒ–。
DTS的大多数应用都是采用相对较å°çš„压缩比ã€å·¥ä½œåœ¨å‡ ä¹Žæ— æŸæƒ…况的模å¼ä¸‹çš„。一般æ¥è¯´ï¼Œæ•°æ®çŽ‡åœ¨1Mb/s的情况下,DTSå¯ä»¥æ供较好质é‡çš„音频。DTS的应用也主è¦æ˜¯åœ¨ç”µå½±ã€CDåŠDVD视频ä¸ã€‚å¦å¤–,DTS所具有的å¯å˜æ¯”特率编ç æ–¹å¼ä½¿å¾—它åŒæ ·å¯ä»¥åº”用于DABåŠDVD的广æ’ä¸ã€‚
7ã€
æ•°å—音频广æ’系统的
10mm Push Button,Push Button Switch,On Off 10mm Push Switch,10mm Push Button Switch
Guangzhou Ruihong Electronic Technology CO.,Ltd , https://www.callegame.com