
UC Berkeley recently published a paper with a concise and clear title: Everybody Dance Now, everyone dance together! That’s right, this laboratory called "mad lab" by netizens has proposed a framework to transfer the movements of professional dancers to people who can’t dance. Whether it’s cool street dance or elegant ballet, the effect is simply God synchronization, fluency and reduction are very high. Let's take a look at this paper with Lunzhi below.
In this article, we propose a simple method for motion migration: first select a single dancing video as the source video, and after a few minutes, the same will be shown on another target video (people who don’t know how to dance). action. We regard this problem as the image-to-image conversion on each frame, while ensuring the smoothness of time and space. Using the motion detector as the representation between the source video and the target video, we learned a mapping from the dancer's motion picture to the target object, and adjusted this setting to make it blend perfectly with the video, and also added Real face synthesis.
First put a video to experience this amazing effect. In the second half of the supplementary case, it also shows the migration of ballet. It can be seen that the thigh part of the ballerina in the original video is obscured by the skirt, but when mapped to the target video, the thigh movement can also be correctly presented, with full results!
Introduction
We propose a method to realize the conversion of actions between different characters in different videos. There are now two videos, one of which is the target we want to synthesize (people who can't dance), and the other is the source video that we imitate (professional dancers). We achieved this movement migration through pixel-based end-to-end channels. This method is different from the nearest neighbor search or the retargeting action in 3D that has been common in the past two decades. Through this framework, we have allowed many untrained people to dance ballet and hip-hop.
In order to realize the movement of each frame between two videos, we must learn a mapping between two characters. Our goal is to perform image-to-image conversion between the source video and the target video. However, we don't have pictures of two target objects making the same action, so we can't directly perform supervised learning on this conversion. Even if two people in the video make a series of the same actions, it is still difficult to extract the posture of each frame, because the body shape and style are completely different.
We found that the key points that can reflect the position of each part of the body can be used as a representation between the two. Therefore, we designed the "middle representation (stickman)" to reflect the action, as shown in the figure:

From the target video, we use the action recognizer to make a combination of (sticker, target person image) for each frame. With such relevant data, we can use the supervised method to learn the image-to-image conversion model between the stickman and the target person. Therefore, our model can generate personalized videos through training. After that, in order to transfer the actions of the source video to the target video, we input the stickman into the trained model to obtain the same target action as the character in the source video. In addition, in order to improve the quality of the generation, we added two elements. In order to make the generated model smoother, we will predict the current frame based on the previous frame. In order to improve the authenticity of the generated face, we also added a trained GAN to generate the face of the target person.
specific method
This task is roughly divided into three steps: action detection, global action normalization and action mapping. The training and migration process is shown in the figure below:
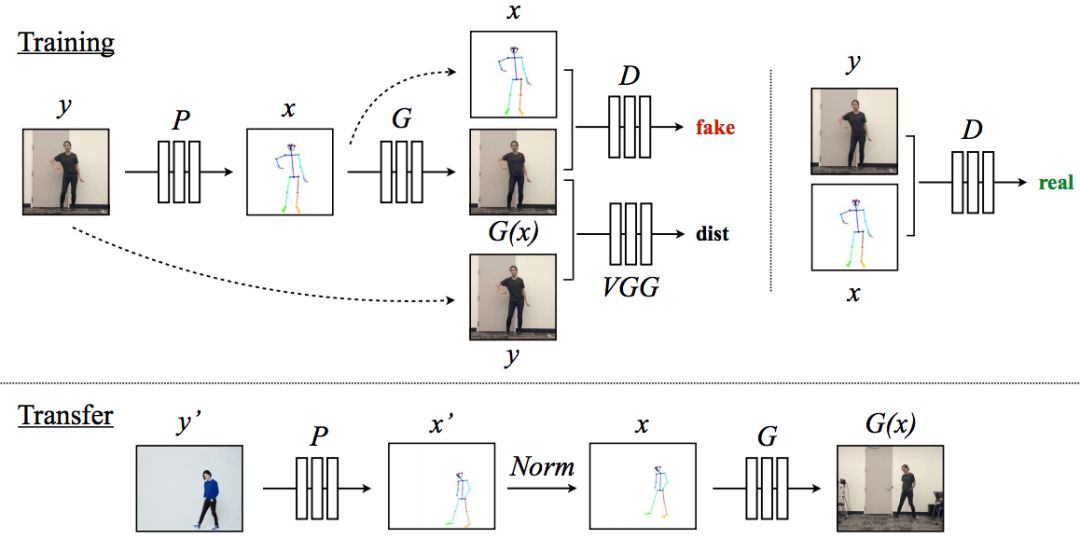
The model creates a stickman corresponding to the character in the target video through the detector P. During training, we learned the mapping G and an adversarial discriminator D. The role of D is to try to determine whether the stickman matches the person in the video.
The next line is the migration process. We use the motion detector P: Y'→X' to obtain the stickman image in the source video. This stickman image is normalized into a stickman designed for the target character. Then apply the trained mapping G to it.
In order to make the effect more realistic, we have also specially added the generation of confrontation network settings to make the face more realistic and the effect is significantly improved.
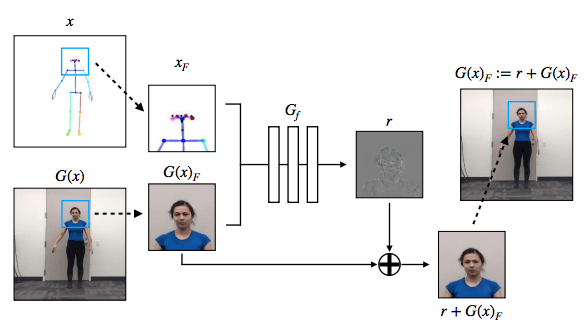
Network Architecture
In order to extract the key points of the body, face and hand motions, we used the most advanced motion detector OpenPose. In the image conversion stage, we used the pix2pixHD model proposed by Wang et al. For the generation of facial images, we did not use the complete pix2pixHD generator, but instead used the pix2pixHD global generator.
Experimental comparison
Since we do not have a standard answer, in order to compare the target person in two different videos, we analyzed the reconstruction process of the target person (that is, the source video person is regarded as the target person). In addition, in order to evaluate the quality of each frame, we measured structural similarity (SSIM) and learned cognitive image patch similarity (LPIPS).
In addition, we also applied a motion detector P on the output of each system to compare the differences between these reconstructed key points and the original motion.


Migration result. The top line is the source target character, the middle is the corresponding "stickman", and the bottom line is the output target character action
We compared the standard pix2pixHD, our model version (TS) with only fluency settings, and the final version of our model (with fluency settings and face GAN). First of all, the comparison of similarity in the three modes is shown in the figure:


In the face area, the quality of the three generated images is compared:


As you can see, the score of our full version model is the best.
discuss
After reading this paper, many people have only one reaction: "Amazing!!!" Indeed, there are many scenarios where such a good-quality video generation technology can be applied in the future, such as movie shooting, VR animation, and so on. But some people also expressed concern, will there be a bunch of fake videos like the previous deepfakes changing face?
There is a rule, custom laptop is called programming laptop cause nearly 90% is used for projects. 15.6 inch laptop for coding and programming is usually equipped with 10th or 11th cpu, 2gb or 4gb graphics optional. 15 inch laptop untuk programming is used on big tender or group for a special jobs. 15.6 inch programming laptop under 30000 is a more competitive one for business or high school students or teachers.
However, here is the recommended laptop for programming, especially for heavy office jobs or university coursework, since double heat-releasing, metal body, bigger battery, FHD screen, high-level cpu, etc. Build the deep and stable foundation to enjoy smooth running experience. Your clients will satisfy it`s excellent performance. Of course, there are other lower specification with tight budget.
As a entry windows laptop for programming, this 14 inch celeron Education Laptop is the most competitive and hottest device for elementary project.
Any other special requirements, just contact us freely.
Programming Laptop,Laptop For Coding And Programming,Programming Laptop Under 30000,Recommended Laptop For Programming,Windows Laptop For Programming
Henan Shuyi Electronics Co., Ltd. , https://www.shuyilaptop.com